정규화
목차
정규화란
정규화(Normalization)의 기본 목표는 테이블 간에 중복된 데이타를 허용하지 않는다는 것이다.
중복된 정보로 인해 이상 현상이 발생하게 된다.
이러한 문제를 해결하기 위해 정규화 과정을 거치는 것이다.
중복된 데이터를 허용하지 않음으로써 무결성(Integrity)를 유지할 수 있으며, DB의 저장 용량 역시 줄일 수 있다.
테이블을 분해하는 정규화 단계가 정의되어 있으며, 테이블이 어떻게 분해되는지에 따라 정규화 단계가 달라진다.
이상 현상(Anomaly)이란
이상 현상이란 테이블에서 일부 속성들의 종속으로 인해 데이터의 중복이 발생하며
이 중복으로 인해 테이블 조작 시 문제가 생기는 현상을 의미

1. 삽입 이상
원하지 않는 자료가 삽입된다든지, 삽입하는데 자료가 부족해 삽입이 되지 않아 발생하는 문제점을 말한다.
- 강의를 수강하지 않은 학생을 추가할 때, 과목 번호와 성적에 null값이 들어가거나 불필요한 데이터를 추가해야 삽입할 수 있는 문제점이 발생한다. 아래와 같은 데이터를 삽입할 수 없다.

- 학생이 수강신청을 할 때 반드시 과목 번호를 알아야 삽입이 가능하다.
2. 삭제 이상
하나의 자료만 삭제하고 싶지만, 그 자료가 포함된 튜플 전체가 삭제됨으로 원하지 않는 정보 손실이 발생하는 문제점을 말한다.
- 학번이 300인 학생이 과목 수강을 취소하면 C-73인 강의에 대한 정보도 모두 삭제된다.

- P1 교수가 강의하는 과목을 취소하는 경우 학번이 123인 학생에 대한 정보도 모두 삭제된다.
3. 갱신 이상
정확하지 않거나 일부의 튜플만 갱신되어 정보가 모호해지거나 일관성이 없어져 정확한 정보 파악이 되지 않는 문제점을 말한다.
- 학번이 123인 학생의 지도교수가 P2로 변경되면, 123인 학생이 수강하는 모든 과목(행)에서의 지도교수를 변경시켜주어야 한다.
정규화 단계
정규화는 1정규화 ~ 6정규화 까지 여러 과정이 존재하지만, 실무에서는 대체로 1~3 정규화까지의 과정을 거치게 됩니다.
제 1정규화(First Normal Form, 1NF)
테이블(Relation)이 제 1정규형을 만족했다는 것은 아래 세 가지 조건를 만족했다는 것을 의미한다.
- 어떤 Relation에 속한 모든 Domain이 원자값(atomic value)만으로 되어 있다.
- 모든 attribute에 반복되는 그룹(repeating group)이 나타나지 않는다.
- 기본 키를 사용하여 관련 데이터의 각 집합을 고유하게 식별할 수 있어야 한다.
예제를 통해 보자. 아래 테이블(Relation)은 제 1정규형의 위의 1,2,3번 조건 중 1번 조건를 위반한 사례이다.
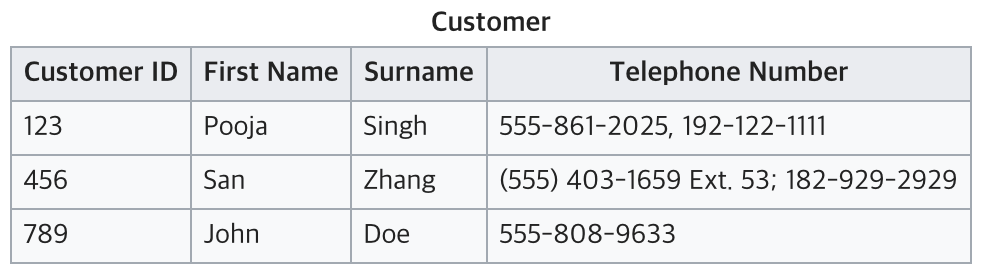
위의 그림을 보면 전화번호가 여러개를 가지고 있기 때문에 이는 atomic하지 않게 되고, 이는 1 정규형을 위반한 것이 된다.
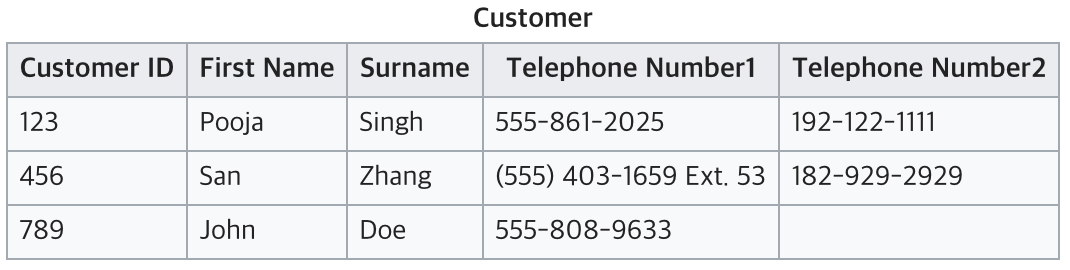
위의 그림은 전화번호 그룹이 반복되는 경우이다.(2번 조건를 위반한 사례) 따라서 이를 재디자인 할 필요가 있다. 아래는 제 1정규화를 만족시키기 위해 바꾼 디자인이다.
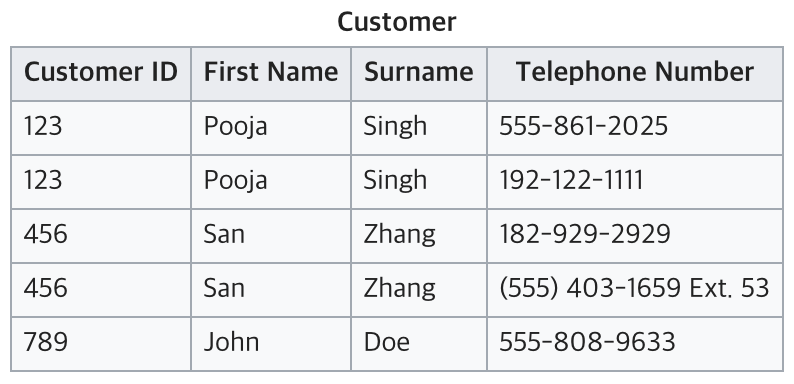
위의 Relation은 ID가 더 이상 고유하게 식별할 수 있는 키가 아니란 것을 확인할 수 있다. 따라서, 3번 조건을 만족하기 위해 아래와 같이 테이블을 나누어 디자인 하는 것이 좋다.
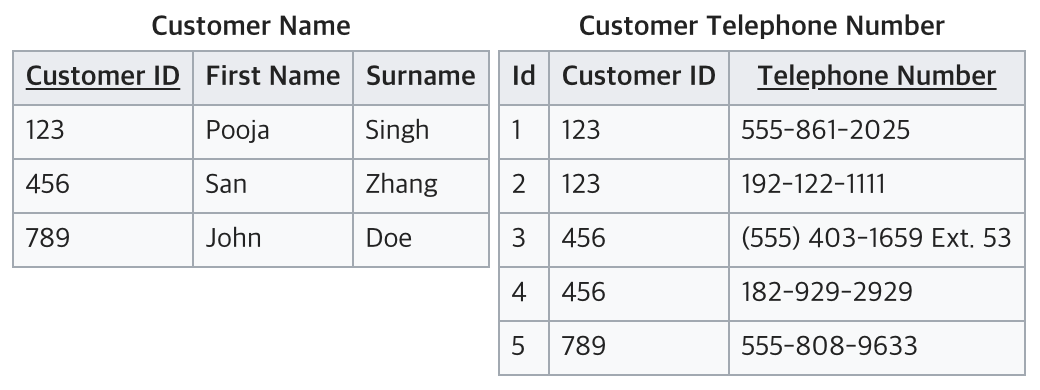
위의 디자인은 Customer Name과 Customer Telephone Number가 One-to-Many의 관계를 형성하는 것을 알 수 있다.
제 2정규화(Second Normal Form, 2NF)
제 2정규화를 수행 했을 경우 테이블의 모든 컬럼이 완전 함수적 종속을 만족한다. (부분 함수적 종속을 모두 제거되었다.) 이를 이해하기 위해서는 부분 함수적 종속과 완전 함수적 종속이라는 용어를 알아야 한다.
함수적 종속 : X의 값에 따라 Y값이 결정될 때 X -> Y로 표현하는데, 이를 Y는 X에 대해 함수적 종속 이라고 한다.
예를 들어 학번을 알면 이름을 알 수 있는데, 이 경우엔 학번이 X가 되고 이름이 Y가 된다.
X를 결정자이라고 하고, Y는 종속자라고 한다.
다른 말로 X가 바뀌었을 경우 Y가 바뀌어야만 한다는 것을 의미한다.
함수적 종속에서 X의 값이 여러 요소일 경우,
즉, {X1, X2} -> Y일 경우, X1와 X2가 Y의 값을 결정할 때 이를 완전 함수적 종속 이라고 하고,
X1, X2 중 하나만 Y의 값을 결정할 때 이를 부분 함수적 종속 이라고 한다.
예시를 들어 살펴보자.
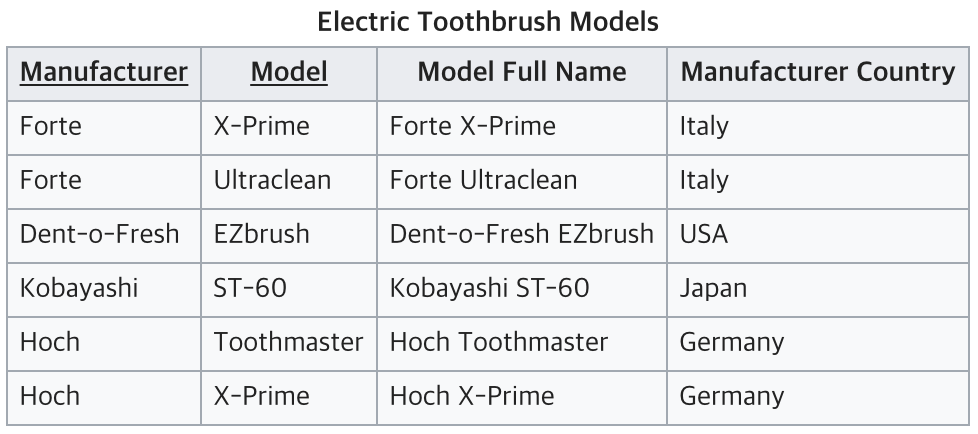
위에서 Model과 Manufacturer를 알면 Model Full Name 필드를 아예 유지하지 않거나 참조하지 않아도 결정되기 때문에, {Model, Manufacturer} -> Model Full Name 이라고 할 수 있다.
하지만 {Model, Manufacturer} -> Manufacturer Country에서 Model과 Manufacturer Country는 아무런 연관 관계가 없기 때문에, Manufacturer Country는 Manufacturer와만 종속관계에 있게 되고 이를 부분 함수 종속이라고 하게 되는 것이다.
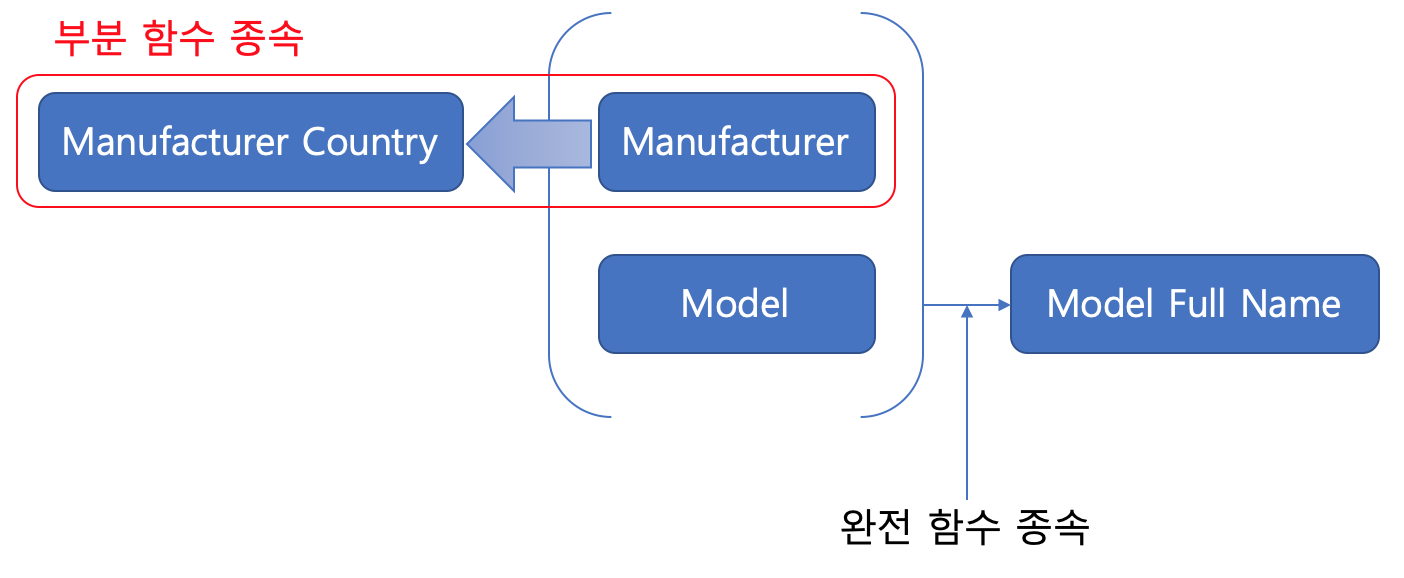
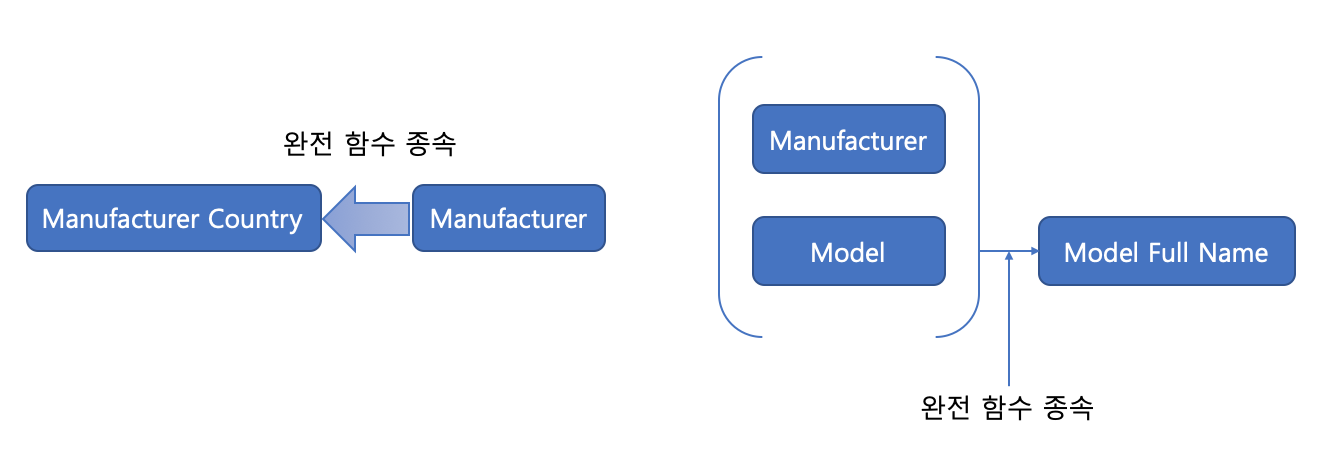
위에서 부분 함수 종속을 제거 하게 되면, 아래와 같은 그림이 된다.
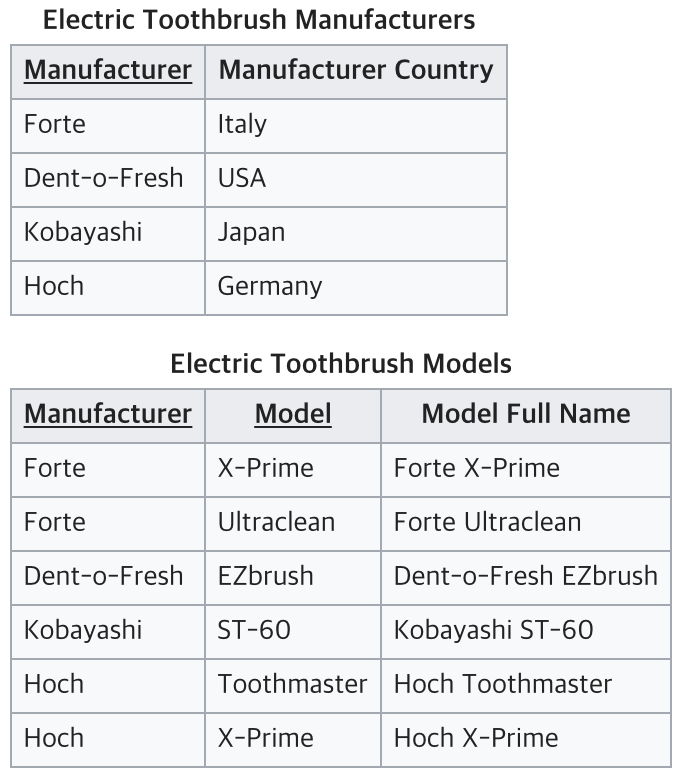
따라서, 부분 함수 종속을 제거한 이후의 테이블은 아래와 같고, 이는 제 2정규형을 만족한 테이블이다.
제 3정규화(Third Normal Form, 3NF)
테이블(Relation)이 제 3정규형을 만족한다는 것은 아래 두 가지 조건을 만족하는 것을 의미한다.
- Relation이 제 2정규화 되었다.(The relation is in second normal form)
- 기본 키(primary key)가 아닌 속성(Attribute)들은 기본 키에만 의존해야 한다. (이행적 함수종속성 제거)
아래는 두 번째 조건이 위반된 사례이다.
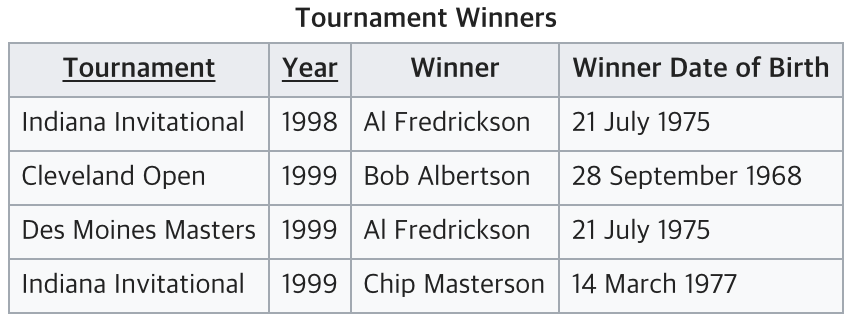
위 테이블에서 {Tournament, Year}가 후보키가 된다.
하지만 Winner Date of Birth은 기본키가 아닌 속성인 Winner를 거쳐 {Tournament, Year}에 의존하고 있는 것을 알 수 있는데, 이는 3NF를 위반한 것이 된다.
따라서 테이블을 아래와 같이 둘로 나누어 주자.
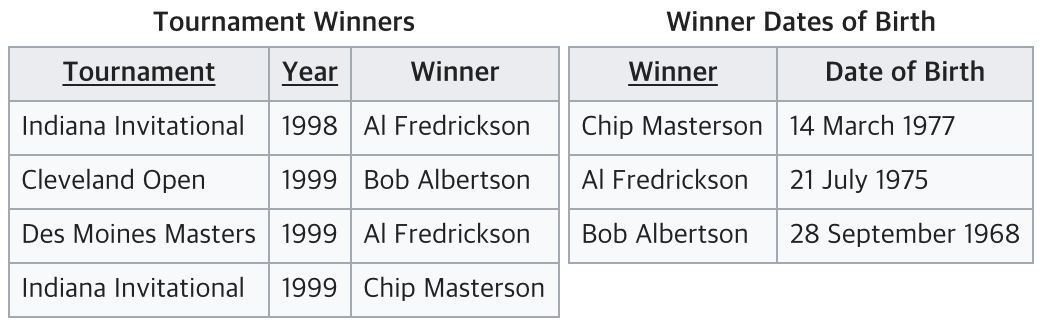
위 테이블은 3NF를 만족한 상태이다.
BCNF(Boyce-Codd) 정규형
테이블 R에서 모든 결정자가 후보키(Candidate Key)인 정규형이다.
일반적으로 제 3정규형에 후보키가 여러 개 존재하고 이러한 후보키들이 서로 중첩되어 나타나는 경우에 적용 가능하다.
아래는 BCNF를 만족하지 않는 3NF 사례이다.

테이블의 슈퍼키는 다음과 같다.
- S1 = {Court, Start time}
- S2 = {Court, End time}
- S3 = {Rate type, Start time}
- S4 = {Rate type, End time}
- S5 = {Court, Start time, End time}
- S6 = {Rate type, Start time, End time}
- S7 = {Court, Rate type, Start time}
- S8 = {Court, Rate type, End time}
- ST = {Court, Rate type, Start time, End time}, the trivial superkey
이 중 S1 , S2 , S3, S4 만이 후보키이다. 예를 들어 S1 ⊂ S5 이므로 S5 는 후보키가 될 수 없다.
테이블이 BCNF를 만족하지 않는 이유는 Rate type -> Court 에서 결정자인 Rate type은 후보키가 아니기 때문이다.
BCNF를 충족하도록 설계를 수정하면 다음과 같다.

4NF / 5NF / 6NF
흔히 4NF는 다치 종속성( MultiValued Dependency, MVD )을 제거하고 한다고 하지만, 폭 넓게 결합 종속성을 제거하는 과정입니다.
A 애트리뷰트를 알면 X라는 다중값( B, C 애트리뷰트 )을 알 수 있을 때, 이러한 종속성을 제거하는 것입니다. ( 참고 예제 - 링크 )
5NF 역시 결합 종속성을 제거하는 과정입니다.
릴레이션에 애트리뷰트 A, B, C가 있을 때, {A,B}, {B,C}, {A,C} 애트리뷰트 조합을 갖는 릴레이션으로 분해될 수 있을 때, 이러한 결합 종속성을 제거하는 것입니다. ( 참고 예제 - 링크 )
6NF 모든 관계가 후보 키와 하나 이상의 다른 (키 또는 비 키) 속성으로 구성됨을 의미합니다. ( 참고 예제 - 링크, 링크 )
6NF는 직교성에 있어 유용한 정규형이지만, 6NF를 하게 되면 릴레이션이 너무 많아지므로 join을 많이 하게 된다는 단점이 있습니다.
각각의 정규형이 만족해야 하는 조건
높은 단계의 정규형은 그 이전 정규형들이 갖는 조건들을 만족해야 합니다.
예를 들어, 4NF는 1NF~BCNF까지의 정규형 조건들을 기본적으로 만족해야 합니다.
수많은 정규형이 있지만 관계 데이터베이스 설계의 목표는 각 릴레이션이 3NF(or BCNF)를 갖게 하는 것이다.
무손실 분해 ( Lossless Decomposition )를 보장해야 한다.
정규화를 진행하는 과정에서 중복을 제거하는 방법으로 릴레이션을 분해합니다. 이 때 원래의 정보를 잃어버리지 않으면서 분해하는 것을 무손실 분해라고 합니다.
즉, 릴레이션을 분해할 때 무손실 분해가 되어야 합니다.
무손실 분해가 되면 분해된 릴레이션을 join 해서 원래의 정보를 얻을 수 있습니다.
정규화의 장점
- 데이터베이스 변경 시 이상 현상(Anomaly) 제거
- 위에서 언급했던 각종 이상 현상들이 발생하는 문제점을 해결할 수 있다.
- 데이터베이스 구조 확장 시 재 디자인 최소화 (데이터 구조의 안정성 및 무결성 유지)
- 정규화된 데이터베이스 구조에서는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 된다.
- 이는 데이터베이스와 연동된 응용 프로그램에 최소한의 영향만을 미치게 되며 응용프로그램의 생명을 연장시킨다.
- 사용자에게 데이터 모델을 더욱 의미있게 제공
- 정규화된 테이블들과 정규화된 테이블들간의 관계들은 현실 세계에서의 개념들과 그들간의 관계들을 반영한다.
- 저장 공간의 최소화 가능
- 효과적인 검색 알고리즘 생성 가능
- 데이터 삽입 시 릴레이션 재구성의 필요성 감소
정규화의 단점
릴레이션의 분해로 인해 릴레이션 간의 연산(JOIN 연산)이 많아진다.
이로 인해 질의에 대한 응답 시간이 느려질 수 있다.
조금 덧붙이자면, 정규화를 수행한다는 것은 데이터를 결정하는 결정자에 의해 함수적 종속을 가지고 있는 일반 속성을 의존자로 하여 입력/수정/삭제 이상을 제거하는 것이다.
데이터의 중복 속성을 제거하고 결정자에 의해 동일한 의미의 일반 속성이 하나의 테이블로 집약되므로 한 테이블의 데이터 용량이 최소화되는 효과가 있다.
따라서 정규화된 테이블은 데이터를 처리할 때 속가 빨라질 수도 있고 느려질 수도 있는 특성이 있다.
→
조회를 하는 SQL 문장에서 조인이 많이 발생하여 이로 인한 성능저하가 나타나는 경우에 반정규화를 적용하는 전략이 필요하다.
반정규화(De-normalization, 비정규화)
정규화된 엔티티, 속성, 관계를 시스템의 성능 향상 및 개발과 운영의 단순화를 위해 중복 통합, 분리 등을 수행하는 데이터 모델링 기법 중 하나이다.
디스크 I/O 량이 많아서 조회 시 성능이 저하되거나, 테이블끼리의 경로가 너무 멀어 조인으로 인한 성능 저하가 예상되거나, 칼럼을 계산하여 조회할 때 성능이 저하될 것이 예상되는 경우 반정규화를 수행하게 된다.
일반적으로 조회에 대한 처리 성능이 중요하다고 판단될 때 부분적으로 반정규화를 고려하게 된다.
반정규화의 대상
- 자주 사용되는 테이블에 액세스하는 프로세스의 수가 가장 많고, 항상 일정한 범위만을 조회하는 경우
- 테이블에 대량 데이터가 있고 대량의 범위를 자주 처리하는 경우, 성능 상 이슈가 있을 경우
- 테이블에 지나치게 조인을 많이 사용하게 되어 데이터를 조회하는 것이 기술적으로 어려울 경우
예를 들어, Courses와 Teachers라는 테이블로 이루어진 정규화된 데이터베이스를 생각해 보자. Courses 테이블에는 teacherlD를 둘 수는 있어도, teacherName이라는 필드를 두지는 않을 것이다. 따라서 강좌 정보와 교사 이름을 함께 나열하고 싶은 경우에는 두 테이블을 조인해야 한다.
어떤 면에서는 멋진 방법이다. 교사가 자신의 이름을 바꿀 경우, 한 곳의 데이터만 갱신하면 된다.
하지만 이 방법의 단점은 테이블이 아주 클 경우 조인을 하느라 불필요할 정도로 많은 시간을 낭비하게 된다는 것이다.
반정규화 과정에서 주의할 점
반정규화를 과도하게 적용하다 보면 데이터의 무결성이 깨질 수 있다.
입력, 수정, 삭제의 질의문에 대한 응답 시간이 늦어질 수 있다.
'CS > DB' 카테고리의 다른 글
| 1.데이터베이스의 종류 (0) | 2024.08.17 |
|---|---|
| 인덱스 (0) | 2021.12.28 |
| 스프링 트랜잭션과 트랜잭션 전파 (0) | 2021.12.28 |
| 트랜잭션 격리수준 (0) | 2021.12.28 |
| 관계형 데이터베이스 (0) | 2021.12.28 |