![[python] 파이썬 리스트(list) 정리 및 예제 (1탄 기본편)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FHLotX%2FbtrcYbBVMWH%2FInj8G1QK4zRFxiK0LbHRk1%2Fimg.png)
출처 : https://blockdmask.tistory.com/425
[python] 파이썬 리스트(list) 정리 및 예제 (1탄 기본편)
안녕하세요. BlockDMask 입니다. 오늘은 파이썬 리스트(list) 자료형에 대해서 정리를 해보려고 합니다. 일련의 여러 값들을 다룰 때 편하게 사용할 수 있는데요. 리스트에 접근하는 방법, 값을넣고
blockdmask.tistory.com
안녕하세요. BlockDMask 입니다.
오늘은 파이썬 리스트(list) 자료형에 대해서 정리를 해보려고 합니다.
일련의 여러 값들을 다룰 때 편하게 사용할 수 있는데요. 리스트에 접근하는 방법, 값을넣고 빼는 방법, 리스트의 길이를 구하거나, 리스트 값을 삭제하는 방법.
리스트에서 +기호와 * 기호가 뜻하는 것, 리스트 정렬하는 방법, 리스트에 있는 여러 함수들 그리고 얕은 복사과 깊은 복사에 대해서 까지 이야기 해보려 합니다.
최대한 간단하고 이해하기 쉽게 작성해 보겠습니다.
그럼 시작해보겠습니다.
<목차>
1. 리스트란?
2. 리스트 덧셈(+), 곱셈(*), 값 변경
3. 리스트 접근 방법 (인덱싱, 값 수정, 슬라이싱)
4. 리스트 항목 삭제와 길이 구하기 (del, len)
5. 리스트의 메서드1 (append, extend, insert, remove, pop)
6. 리스트의 메서드2 (clear, index, count, sort, reverse, copy)
7. 리스트 복사에 대해서 (얕은복사, 깊은복사)
파이썬 리스트 2탄 응용편 [바로가기]
1. 파이썬에서 리스트(list)란?
> 리스트 타입의 설명
리스트는 데이터들을 잘 관리하기 위해서 묶어서 관리할 수 있는 자료형 중의 하나 입니다.
사전에 리스트를 찾아보면 아래와 같이 나오게됩니다.
다수의 품명(品名)이나 인명(人名) 등을 기억하거나 점검하기 쉽도록 특별한 순서로 적어 놓은 것. 순화어는 `목록', `명단'.
우리는 이걸 보고 리스트가 점검하거나 기억하기 쉽도록 특별한 순서로 적어놓은 것. 이라는 것을 알 수 있고, 이걸 프로그래밍 언어 차원에서 본다면 데이터들을 잘 관리할 수 있도록 순서를 정해서 관리하는 데이터 타입의 하나 이다. 라고 생각하면 되겠습니다.
리스트 자료형 혹은 배열을 말할때 항상 교수님들은 이런예제를 사용했었습니다.
아파트에 101호 부터 1201호 까지 하나씩 변수로만들게 되면 아래와 같이 하나하나 변수를 만들어 주어야합니다.
a1 = 101
a2 = 201
a3 = 301
...
a10 = 1001
a11 = 1101
a12 = 1201
이게 지금은 열두개라서 그래도 사람손으로 해도 가능은 하지만, 동 수가 많아지고 호수도 더 많아진다면 100개 1000개 의 변수를 하나하나 일일히 만들수는 없지 않을까요?
그래서 한번에 변수를 묶어서 땡처리 할 수 있게 리스트 자료형이 나오게 된 것 입니다.
101호 부터 1201호 까지 리스트로 나타내면 아래와 같습니다.
a = [101, 201, 301, 401, 501, 601, 701, 801, 901, 1001, 1101, 1201]
어떤가요? 여전히 호수는 일일히 쳐야하지만, 변수가 12개가 생기는게 아니라 리스트 타입의 변수 딱 1개만 만들어서 묶어서 처리할 수 있게 되었죠?
101부터 1201 까지 치는것도 비효율적으로 보인다 싶다면. 그럼 101, 201처럼 규칙이 있는 자료형은 for 반복문이나 while 반복문을 통해서 자료형을 또 넣거나 할 수 있겠죠?
또한, 리스트는 시퀀스 데이터라고 합니다. 시퀀스라는 것은 데이터에 순서가 존재한다는 뜻입니다. 그렇기 때문에 우리는 리스트 안에 있는 데이터를 순서대로 접근이 가능하고, index를 이용해서 리스트[몇번지=index]에 한번에 접근가능하기도 합니다.
> 리스트를 만드는 방법
파이썬에서 리스트는 아래와같은 생김새를 가지고 있습니다.
리스트변수이름 = [요소1, 요소2 ...]
이렇게 대괄호 안에 요소들이 순서대로 존재하고 있습니다.
만약 안에 요소를 가지고 있지 않는다 해도 리스트 타입은 맞으며, 요소가 없는 리스트 타입. 즉 비어있는 리스트 인 것 입니다.
파이썬에서 리스트를 만드는 방법은 2가지가 존재합니다.
> 대괄호를 이용하는 방법
a = [1, 2, 3, 4, 5]
b = ['blockdmask', 2, 4, 'blog']
c = []
이렇게 대괄호를 이용해서 리스트를 만들 수 있으며, 리스트 내부에 값은 스트링이 오든, 숫자가 오든 데이터 타입이 통일되지 않아도 상관없습니다.
또한, c를 보면 아무것도 넣지 않은 [] 대괄호만 있는걸 보실수 있는데, 이것은 위에서 말했듯, 요소가 없는 비어있는 리스트를 말합니다.
> list()를 이용한 방법
d = list()
이렇게 list()를 이용해서 리스트를 만들수 있습니다. 하지만, 이것은 비어있는 리스트만 뜻하게 됩니다.
2. 파이썬 리스트의 덧셈, 곱셈, 값 변경에 대해서
> 덧셈 - 리스트를 붙인다.
덧셈 연산자 + 를 이용해서 리스트끼리 덧셈을 할 수 있습니다.
덧셈을 하게되면 리스트가 연결이 되고, 그 연결된 하나의 리스트가 생성됩니다.
1 2 3 4 5 |
# 리스트 덧셈 a = ["BlockDMask", 333] b = [1, 2, 3] print(a + b) |
cs |

이렇게 리스트 a ['BlockDMask', 333] 와 리스트 b [1,2,3]을 더하면 하나의 또다른 리스트인 ['BlockDMask', 333, 1, 2, 3]이 생성되는 것을 알 수 있습니다.
리스트 덧셈은 리스트 이어 붙이기 입니다.
아래 설명할 리스트의 extend 함수와는 다릅니다.
> 곱셈 - 리스트를 반복한다
곱셈 연산자 * 를 이용해서 리스트를 곱할 수 있습니다.
n을 곱하게 되면 n 번만큼 리스트를 반복해서 만들어 줍니다.
2번 곱하면 리스트가 2번 반복이 되고, 0을 곱하게 되면 빈 리스트가 됩니다.
1 2 3 4 5 6 7 8 9 |
# 리스트 a = [1, 2, 3] b = a * 3 print(b) c = a * 0 print(c) |
cs |

이렇게 리스트를 n번 곱하게 되면 n번 만큼 리스트를 앞에서 부터 뒤까지 반복해서 새로운 리스트를 만들어 줍니다.
0을 곱하게 되면 빈 리스트가 생성 됩니다.
3. 파이썬 리스트의 인덱싱과 슬라이싱에 대해서
> 리스트 인덱싱1 : 리스트 검색, 접근
파이썬의 리스트는 시퀀스 데이터 타입이기 때문에 인덱스를 이용해서 접근을 할 수 있습니다.
즉, 각 요소 마다 자리표가 있어서 우리는 리스트 a에 1번 손님 앞으로 나오세요~
이게 가능하다는 그말 입니다. 그걸 코드로 한번 볼까요?
앗 그리고 리스트의 자리표(index)는 0번부터 시작하게 됩니다.
그럼 index 1번 손님은 두번 째 손님이겠죠?
간단하게 예제를 보면
리스트 a = ['b', 'l', 'o', 'c', 10, 11] 라 하면
a[0]는 'b'를 가리키고
a[1]은 'l'을 가리킵니다.
...
a[5]는 11 을 가리킵니다.
a[6]은 에러가 납니다. 없는 값을 가리키려고 하기 때문이죠.
그래서 인덱스는 "리스트의 길이 -1" 까지가 끝 입니다.
아 그리고!
파이썬에서는 신기하게도 리스트에서 마이너스 인덱스를 통해서 끝에서 부터 접근이 가능합니다. 그게 무슨 뜻인지는 예제로 한번 확인해 볼까요?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 리스트 인덱싱 # 길이가 8인 리스트 a = [101, 102, 'b', 'l', 'o', 103, 104, 105] # 인자 접근 print(f'a[0] : ') print(f'a[1] : ') print(f'a[2] : ') # ... print(f'a[7] : ') # print(f'a[8] : ') - error # 그럼 마이너스로 접근이 가능할까요? print(f'a[-1] : ') print(f'a[-2] : ') # ... print(f'a[-8] : ') # print(f'a[-9] : ') - error Colored by Color Scripter |
cs |

결과 값을 보면 길이가 8인 리스트에서 접근 할 수 있는 인덱스는
양수 : 왼쪽에서 오른쪽 방향은 0부터 7까지 접근이 가능하고
음수 : 오른쪽 에서 왼쪽 방향은 -1 부터 -8 까지 접근이 가능합니다.
음수를 통해서 뒤에서 부터 접근이 가능한것은 매우 신기하고 유용할것 같네요.
그럼 정리를 해보면
길이가 N인 리스트를 인덱스 할 수 있는 범위는
양수 0 ~ N-1 까지
음수 -N ~ -1 까지
결론적으로 -N 부터 N-1 구간 까지 접근이 가능합니다.
> 리스트 인덱싱2 : 리스트 값 수정
우리는 위에서 배운 인덱싱을 가지고 리스트의 특정 요소의 값을 수정할 수 있습니다.
리스트의 맨 첫번째 인자를 10으로 변경하고 싶다고 하면 인덱싱을 이용해서 해당 값에 접근을 하고 그 값에 = 을 이용해서 원하는 값(=10)으로 넣어줍니다.
a[0] = 10
정리해보면 이런식으로 가능하겠죠?
리스트[N] = 값
예제로 한번 보겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 리스트 값 수정 b = [222, 333, 444, 555] print(f'b : \n') b[0] = 10 print(f'b[0] = 10') print(f'b : \n') b[-2] = 'BlockDMask' print(f'b[-2] = \'BlockDMask\'') print(f'b : \n') b[3] = 1000 print(f'b[3] = 1000') print(f'b : ') Colored by Color Scripter |
cs |

이렇게 인덱스를 이용해서 리스트의 값을 변경할 수 있습니다. 간단하죠?
> 리스트 슬라이싱 : 리스트 자르기
리스트 슬라이싱이라는것은 리스트를 잘라버린다는것 입니다. 리스트를 다루다 보면 필요한 부분만 잘라서 쓰고 싶고, 필요없는 부분은 잘라 내야하는 경우가 있습니다.
파이썬에서는 슬라이싱을 [] 대괄호에서 콜론 : 을 이용해서 진행을 합니다.
: 콜론은 ~에서 ~까지를 나타내는 것을 말합니다.
리스트 a = [100, 101, 102, 103, 104] 라는것이 존재하고, 우리는 101번부터 103번까지의 값만 필요하다고 했을때.
위에서 리스트 인덱싱에서 배운걸 보면 a[1]는 101을 가리키고 a[3]는 103 값을 가리킬 것 입니다.
그럼 슬라이싱을 이용해서 이렇게 표현할 수 있습니다.
a[1:4]
이렇게 표현을 하면 "리스트 a에서 index 1번부터 3번까지를 잘라서 리스트로 반환해라". 하는 명령이 됩니다. 중요한건 반환값도 리스트 라는것입니다.
어 근데 a[1:3]이 아니라 a[1:4]네요? 그럼 a[1]부터 ~ a[3] 까지 자른다는 것을 a[1:4] 까지로 표현을 하는걸 보면 뒤에있는 :4는 포함하지 않는 구간이라는 거네요.
4-1 index 까지만 가지고 온다는 거군요.
정리를 해보면
리스트[원하는 시작 index : 원하는 끝 index + 1] 를 하면
해당 리스트의 원하는 부분을 잘라서 리스트로 반환해주는것을 리스트 슬라이싱 이라고 합니다.
그럼 슬라이싱 중에 [:], [:M], [M:] 이렇게 앞뒤를 생략한것들은 무슨 뜻인지 예제에서 확인해보겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# 리스트 # 길이가 8인 리스트 a = [101, 102, 'b', 'l', 'o', 103, 104, 105] # a[1] 부터 ~ a[2] 까지 슬라이싱 print(f'a[1:3] : ') # a[1] 부터 ~ a[6] 까지 슬라이싱 print(f'a[1:7] : ') # a[1] 부터 ~ a[7] 까지 슬라이싱 (리스트 끝 까지1) print(f'a[1:8] : ') # a[1] 부터 리스트 끝까지 슬라이싱 (리스트 끝 까지2) print(f'a[1:] : ') # 리스트 맨 앞에서 부터 맨 뒤 끝 까지 print(f'a[:] : ') # 리스트 맨 앞에서 특정 부분 까지 print(f'a[:3] : \n') # 리스트 반으로 뚝딱 나누기 1 print(f'a[:4] : ') print(f'a[4:] : ') # 리스트 반으로 나누기 2 # 리스트 길이를 가지고 오는 len 내장함수 이용 w = int(len(a) / 2) print(f'a[:w] : ') print(f'a[w:] : \n') # 마이너스는 통할까? print(f'a[-2:] : ') print(f'a[-1:] : ') print(f'a[-5:-1] : ') print(f'a[:-5] : ') Colored by Color Scripter |
cs |
결과 확인
a = [101, 102, 'b', 'l', 'o', 103, 104, 105]

결과를 보시면
1. 슬라이싱은 리스트 a의 a[N:M] 이라고 한다면 아래의 식을 만족합니다.
a[N] <= x < a[M]
a[N] <= x <= a[M-1]
N을 포함한 인덱스 부터 M을 포함하지 않는 인덱스 까지를 자르는 기능을 합니다.
2. 슬라이싱을 할때 맨 앞을 비워둔다면 a[:M] 이렇게 표현할 수 있으며 이는 아래의 식을 말합니다.
a[0] <= x < a[M]
a[0] <= x <= a[M-1]
3. 뒤를 비워두는 a[N:] 이런 식이라면
a[N] <= x < a[len(a)]
a[N] <= x <= a[len(a) - 1]
len(a)는 리스트의 길이를 말합니다.
4. a[:] 이처럼 양쪽을 비워서 슬라이싱을 한다는 것은 리스트 전체를 복사하는것과 동일합니다.
a[0] <= x < a[len(a)]
a[0] <= x <= a[len(a) - 1]
5. 예제 마지막을 보시면 음수 index도 슬라이싱을 할 수 있다는걸 볼 수 있습니다.
4. 파이썬 리스트의 길이, 삭제에 대해서
> len 함수 - 리스트의 길이를 구하는 함수
내장함수 len을 이용해서 리스트의 길이를 구할 수 있습니다.
len(리스트) 이면 리스트의 길이를 반환해줍니다.
1 2 3 4 5 6 |
# 리스트 길이 구하기 c = [1, 2, 3, 4, 5, 6, 7] print(f"c : ") print(f"len(c) : ") |
cs |
결과값.

> del 함수 - 리스트의 특정 요소 혹은 리스트 특정 범위를 삭제
del(리스트 범위 or 리스트 특정 요소)
리스트 슬라이싱을 이용해서 리스트에서 특정 범위 만큼을 삭제할 수 있습니다.
리스트 인덱싱을 이용해서 리스트에서 특정 요소를 삭제 할 수 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 리스트 삭제, 특정 위치 삭제, 특정 범위 삭제 c = [100, 200, 300, 400, 500, 600, 700] print(f"c : ") # 특정 위치 삭제 del(c[1]) print(f"del(c[1])") print(f"c : \n") # 범위 삭제 del(c[1:4]) print(f"del(c[1:4])") print(f"c : \n") Colored by Color Scripter |
cs |

결과를 보시면 del() 함수를 이용해서 리스트의 특정 범위를 삭제하거나, 특정 값을 삭제 할 수 있음을 확인 할 수 있습니다.
c = [100, 200, 300, 400, 500, 600, 700] 인 리스트에서
del(c[1]) 을 하게 되니 1번째 인덱스인 200이 삭제되고
c는 [100, 300, 400, 500, 600, 700] 만 남게 되는것을 볼 수 있습니다.
이 상태에서 del(c[1:4]) 를 하게 되니 1~3 인덱스인 300, 400, 500 값이 삭제되어
c는 [100, 600, 700] 이 되는걸 볼 수 있습니다.
** len 함수와 del 함수는 리스트 전용으로만 딱 쓸수있는 함수가 아니라, 다른 객체에도 사용할 수 있는 파이썬 내장 함수 입니다.
5. 리스트 메서드 append, insert, remove, pop, extend
list.append(x) - 리스트에 값 추가
리스트의 append 함수를 이용해서 리스트의 끝에 값 x를 추가하는 함수 입니다.
1 2 3 4 5 6 7 8 9 |
a = [2, 9, 4] print(a) a.append('k') print(a) a.append(100) print(a) |
cs |

결과를 보면 append 함수를 호출하여 특정 값을 추가할 때 마다 리스트의 맨 뒤에 값이 추가 되는것을 확인할 수 있습니다.
list.insert(a, b) - 특정 위치에 값 추가
리스트의 a위치에 b 값을 추가하는 함수 입니다.
a는 index 를 말합니다.
1 2 3 4 5 6 7 8 9 |
c = [22, 44, 66, 88] print(c) c.insert(0, 'k') print(c) c.insert(3, 'm') print(c) |
cs |

c.insert(0, 'k') 를 보면 index가 0인 위치에 'k' 값이 들어가 있고, 나머지 리스트는 뒤로 밀린것을 볼 수 있습니다.
list.remove(x) - 리스트에서 특정 값 제거
리스트에서 특정 값 x를 찾아서 제거하는 함수입니다.
해당 값 x가 여러개 있다면? x가 없다면? 어떻게 될까요?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
c = [22, 44, 66, 88, 44, 11, 44] print(f'c : ') # remove() 값이 하나일때 c.remove(66) print(f'c.remove(66) : ') # remove() 값이 두개 이상일때 c.remove(44) print(f'c.remove(44) : ') # remove() 값이 없을때 (error) c.remove(1000) print(f'c.remove(1000) : ') Colored by Color Scripter |
cs |
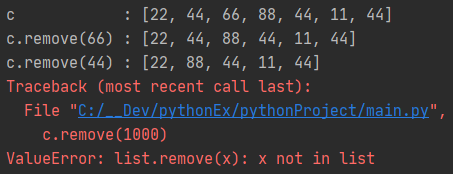
결과를 보셨듯
remove(x)에 x 값이 리스트에 존재하면 x 값을 지워줍니다.
x가 리스트에 여러개 있다 해도, 맨 처음 x를 지워 줍니다.
x가 리스트에 존재하지 않는다면 에러가 발생합니다.
list.pop() - 리스트 맨 마지막 값 반환 후 삭제
리스트에 있는 맨 마지막 값을 반환한 후에 리스트에서 해당 값을 삭제하는 함수 입니다.
맨 마지막 값을 제거 하기 위한 용도로만 사용하셔도 되고,
맨 마지막 값을 읽어오고 제거 하기 위한 용도로 사용 할 수 도 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
a = [9, 8, 7, 6, 5] print(f'a : \n') b = a.pop() print(f'a.pop()의 반환 : ') print(f'a : \n') c = a.pop() print(f'a.pop()의 반환 : ') print(f'a : \n') d = a.pop() print(f'a.pop()의 반환 : ') print(f'a : \n') |
cs |

a.pop()이 불릴때 마다 리스트 맨 뒤에 있는 값이 사라지고, 해당 값은 a.pop의 반환값으로 되는것을 확인할 수 있습니다.
list.extend(list2) - 리스트에 다른 리스트2 연결
리스트1에 리스트2를 붙이고 싶을때 사용하는 함수 입니다.
extend( 매개변수 ) 함수의 매개변수에는 무조건 리스트가 와야합니다.
1 2 3 4 5 6 7 8 9 10 11 12 |
a = [6, 5] b = [3, 2, 1] c = ['blockdmask', 'blog'] print(a) a.extend(b) print(a) a.extend(c) print(a) |
cs |

list1.extend(list2)
매개변수로 들어온 list2가 list1의 뒤에 붙여진것을 확인할 수 있습니다.
list1 리스트는 길이가 길어지게 되고, 따로 출력하진 않았지만 list2는 그대로 입니다.
이렇게 extend를 이용해서 리스트를 붙일 수 있습니다.
리스트 + 연산자와 extend의 다른점은
list1 + list2 는 리스트 두개의 리스트를 연결해서 새로운 list3을 반환하는 것이고 그렇기 때문에 list3 = list1 + list2 이런식으로 해야 이어진 리스트를 받을 수 있습니다.
하지만
list1.extend(list2)는 list1 리스트 객체에다가 list2를 붙이고, list1 객체를 그대로 사용할 수 있다는 점이 다릅니다.
6. 파이썬 메서드 copy, reverse, sort, count, index, clear
list.copy() - 리스트 복사
리스트를 복사할 수 있는 함수 입니다. 복사한 리스트를 반환하는 함수 입니다.
1 2 3 4 5 6 7 8 |
a = [100, 200, 300] b = a.copy() print(a) print(b) print(id(a)) print(id(b)) |
cs |

잘 복사 되었고, 주소값이 다른걸 보면 깊은 복사로 인해서 아예 다른 리스트가 생긴것을 볼 수 있습니다.
list.reverse() - 리스트 뒤집기
리스트의 내부 요소들을 싹 뒤집습니다.
뒤집은 리스트를 반환하는 것이 아니라. 현재 리스트를 뒤집습니다.
1 2 3 4 5 |
a = [100, 200, 300] a.reverse() print(a) |
cs |

reverse 함수로 인해서 리스트 a의 내부 요소들이 다 뒤집힌 것을 볼 수 있습니다.
list.sort() - 리스트 정렬
리스트의 내부 요소를 정렬해주는 함수입니다.
기본적으로는 오름차순으로 정렬이 됩니다.
(작은것 이 앞으로 오고, 큰 값들이 뒤로 가는 정렬방식)
sort 함수에서 주의해야할 것은 내부 요소의 데이터 타입이 같아야합니다.
즉, 비교가 가능한 요소들만 있어야지 sort 함수가 작동할 수 있습니다.
간단히 이야기해서 ["blockdmask", 1, 2, 3, 'a'] 이런 리스트는 내부에 문자열도 있고 정수도 있고 데이터 타입이 통일되지 않아서 비교가 불가능 하기 때문에 정렬이 불가능 한 것 입니다.
비교 불가능 => 정렬 불가능
그럼 이제 예제로 한번 살펴볼까요?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 정렬 가능! a = [300, 200, 800, 400, 500, 100] a.sort() print(a) # 정렬 가능! b = ['c', 'fff', 't', 'k', 'a'] b.sort() print(b) # 정렬 불가능! c = ['a', 100, 1, 5, 'c', 'b', 'l', 'o'] c.sort() print(c) Colored by Color Scripter |
cs |

결과값으로 보셨듯,
리스트 내부에 자료형이 int 타입으로 통일된 a 리스트와 리스트 내부의 자료형이 string 타입으로 통일된 b 리스트는 문제 없이 sort() 된 것을 확인할 수 있습니다.
그렇지만 int, string 타입이 섞여있는 c 리스트는 에러가 난 것을 볼 수 있습니다.
에러 문구를 잘 보면 int 타입과 str 타입은 "<" 비교를 할 수 없다. 그러므로 sort() 함수를 쓸 수 없다. 입니다.
list.count(x) - 리스트 값 x 의 개수 세기
리스트 내부에 매개변수로 전달받은 x와 같은게 몇개가 있는지 세서 그 개수를 반환하는 함수 입니다.
리스트 내부에 x와 같은 값의 개수 반환.
1 2 3 4 5 6 7 8 9 10 |
a = ['b', 'l', 'o', 'c', 'k', 'd', 'm', 'a', 's', 'k'] print(f"a = ") # 리스트에서 'k' 개수 찾기 print(f"a.count('k') : ") # 리스트에는 없는 'z' 개수 찾기 print(f"a.count('z') : ") Colored by Color Scripter |
cs |

list.count(x) 함수에 인자로 찾고 싶은 것을 넣으면 개수를 잘 반환해주는걸 볼 수 있습니다.
list.index(x) - 리스트 값 x의 위치(index) 값 반환
리스트 내부에 값 x의 위치를 index 로 반환하는 것 입니다.
x가 여러개있다면 맨 처음에 나온 x의 index를 반환하게 됩니다.
x가 리스트 내부에 없다면 어떤 값을 반환할까요?
1 2 3 4 5 6 7 8 9 10 11 12 |
a = ['b', 'l', 'o', 'c', 'k', 'd', 'm', 'a', 's', 'k'] print(f"a = ") # 리스트에서 'k' 위치 찾기 (하나인 경우) print(f"a.index('d') : ") # 리스트에서 'k' 위치 찾기 (여러개인 경우) print(f"a.index('k') : ") # 리스트에서 'z' 위치 찾기 (없는 경우) print(f"a.index('z') : ") Colored by Color Scripter |
cs |

결과 값을 보셨듯
list.index(x) 함수는 찾고자 하는 x 값의 위치의 index 값을 반환합니다.
한 개가 있다면 당연하게도 그 위치를 반환하겠죠.
여러개가 있다 해도 맨 처음 찾은 x의 위치를 반환하게 됩니다.
그렇지만 만약에 리스트 내부에 찾고자 하는 x가 없는 경우 에러가 발생하게 됩니다.
list.clear() - 리스트에 저장된 모든 값 삭제
리스트 내부에 존재하는 모든 값들을 삭제 합니다.
리스트 자체를 삭제하는게 아니라 내부 값들만 삭제하기 때문에
리스트 객체 자체는 남아있고, 내부 값이 없는. 비어있는 리스트가 됩니다.
1 2 3 4 5 6 |
a = ['blockdmask', 1, 2, 3] print(a) a.clear() print(a) |
cs |

이렇게 clear() 함수를 이용하면 리스트 내부에 있는 모든 값들을 삭제하여, 빈 리스트가 됩니다.
7. 파이썬 리스트 깊은 복사과 얕은 복사에 대해서
깊은 복사는 말 그대로 복사를 해서 각각 독립적인 리스트가 되는것이고
얕은 복사는 복사는 했지만 얕게 해서 겉에만 복사된 느낌이고 실제로는 같은 리스트를 가리키고 있는것을 말합니다.
리스트 a가 있었고 a를 복사한 리스트 b가 있다고 했을때
b의 값을 변경했을때
a가 바뀐다 -> 얕은복사
a가 안바뀐다 -> 깊은복사
이것입니다.
좀더 깊게 이야기하면
얕은 복사를 하면 복사가 아닌 참조가 되어서, 같은 주소를 가리키는 변수가 하나 생긴것 뿐입니다.
깊은 복사는 새롭게 리스트를 복사하여 주소값이 아예 다른 별개의 변수가 생긴 것입니다.
예제에서 한번 확인해 볼까요?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 리스트 얕은 복사, 깊은 복사 # 얕은 복사 (이어져있음) a = [100, 200, 300, 400, 500, 600, 700] b = a print(f"1. 얕은 복사") print(f"b = a") print(f"id(a) = ") print(f"id(b) = \n") b[2] = "BlockDMask" print('b[2] = "BlockDMask"') print(f"a = ") print(f"b = \n") # 깊은 복사 (독립) c = [100, 200, 300, 400] d = c.copy() e = c[:] print(f"2. 깊은 복사") print(f"d = c.copy()") print(f"e = c[:]") print(f"id(c) = ") print(f"id(d) = ") print(f"id(e) = \n") d[1] = "Blog" e[3] = 1212 print('d[1] = "Blog"') print('e[3] = 1212') print(f"c = ") print(f"d = ") print(f"e = \n") Colored by Color Scripter |
cs |
결과 값 확인
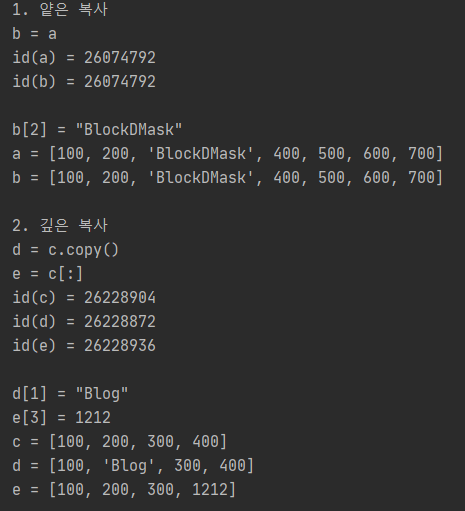
얕은 복사는 = 대입으로 진행을 하고
깊은 복사는 copy 함수나 [:] 슬라이싱을 이용해서 진행하는것을 확인할 수 있습니다.
얕은 복사를 진행한 리스트 a, b는 주소값이 동일한것을 볼 수 있으며, 그렇기 때문에 리스트 b의 값을 변경했을때 리스트 a의 값도 변경된 것을 볼 수 있습니다.
깊은 복사를 진행한 리스트 c, d, e는 각각 주소값이 다른것을 볼 수 있습니다.
그렇기 때문에 리스트 d, e 의 값을 각각 변경해도 다른 리스트에는 영향이 없는 것을 볼 수 있습니다.
저는 얕은 복사 깊은 복사가 반대로 외워져서 이런방식으로 생각하고 있습니다.
얕은 복사는 얕게 헤어져서 계속 질척거리게 이어진 느낌.
깊은 복사는 깊게 사귀다가 아예 헤어져서 남남이 된 느낌.
아마 저만 이렇게 외울것 같습니다. 하하.
이번 포스팅은 매우매우 길었네요. 간만에 길어서 오래 걸렸습니다. 2장으로 나누지 않고 진행 하려 했는데, 어쩔수 없이 나누어 졌습니다.
이번 포스팅에서는 파이썬 기본에서 이정도의 리스트 정보, 사용법은 딱 알고 넘어가시면 좋을것 같습니다. 감사합니다. 힘들게 작성한 만큼 글을 읽은 분들께 도움이 되었으면 좋겠습니다.
출처: https://blockdmask.tistory.com/425 [개발자 지망생]
'프로그래밍 언어별 tools > 파이썬' 카테고리의 다른 글
| 리스트 정렬 sort, sorted 활용법 (0) | 2021.10.01 |
|---|---|
| 파이썬 reduce 함수 사용법 (0) | 2021.09.29 |
| 파이썬 Counter (0) | 2021.09.29 |
| [python] 파이썬 join 함수 정리 및 예제 (문자열 합치기) (0) | 2021.08.23 |
| [python] 파이썬 리스트(list) 정리 및 예제 (2탄 응용편) (0) | 2021.08.23 |